
Science cluster & challenges

Summary
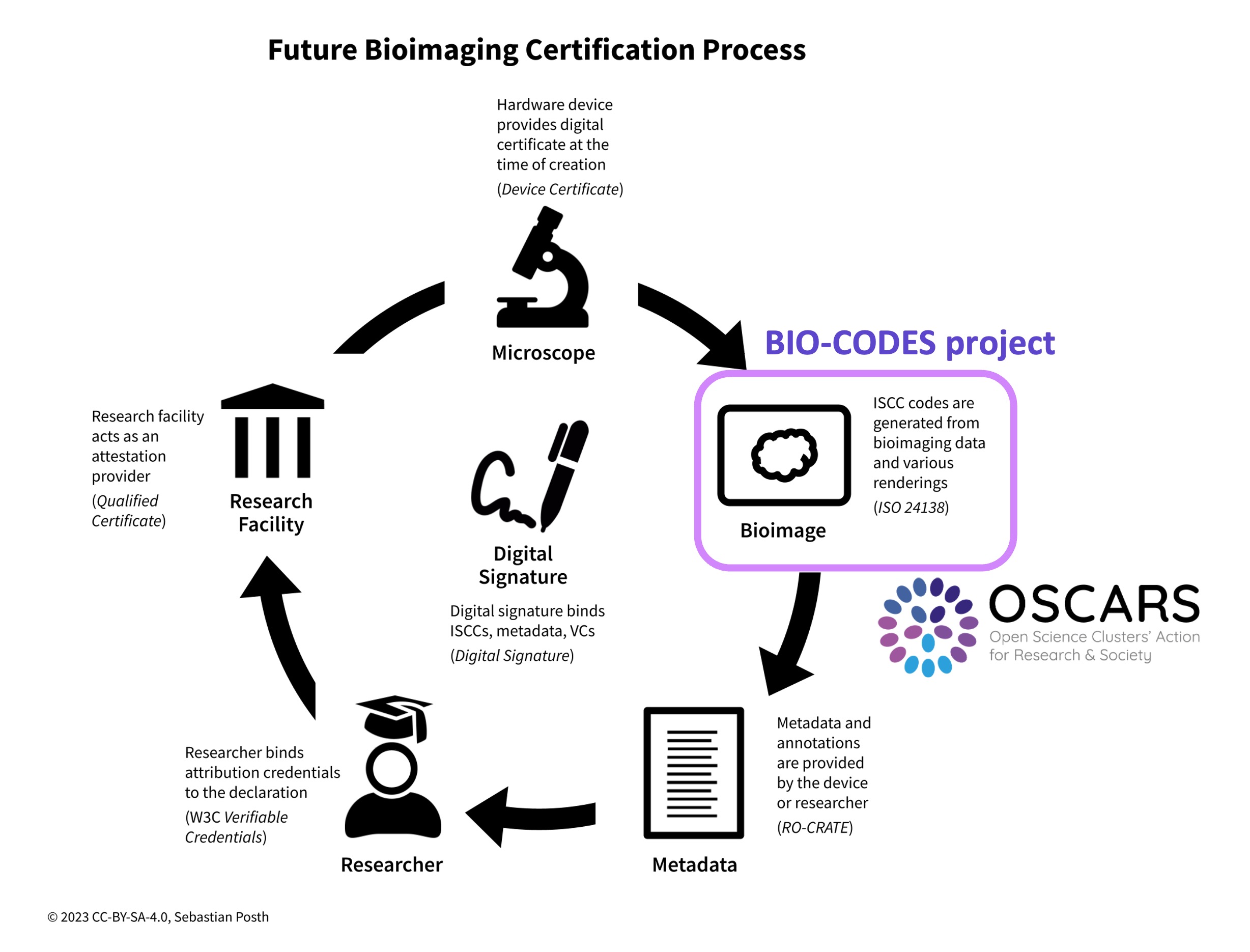
(Standardised) content identification is becoming an essential requirement for bioimaging data reuse and the seamless integration of bioimaging data into AI models. Transparency regarding the origin of data, distinguishing between conventionally generated and AI-generated data, is essential to maintain data integrity and facilitate informed analysis. In this context, the International Standard Content Code - ISCC is a new, open-source identification system and global ISO standard, ensuring transparency, accessibility, and widespread adoption. The BIO-CODES project seeks to enhance the AI-readiness of bioimaging data by developing and implementing content-based identifiers, using ISCC. The project addresses the increasing complexity of bioimaging data, ensuring it adheres to FAIR principles, and prepares datasets for reliable use in AI-driven analyses. By integrating globally unique references into key platforms, such as OMERO, BIO-CODES aims to advance data integrity and streamline bioimage certification processes, ensuring transparency and reproducibility.
Challenge
Open Science project, Industry cooperation, Main RI concerned, Cross-domain/Cross-RI
As bioimaging data grows in complexity, much of it remains non-compliant with FAIR principles, which complicates data reuse and AI integration. Current methods for identification and certification of bioimaging data lack the robustness needed for generative AI models, risking data integrity, data reliability, thus scientific reproducibility. Addressing these gaps is essential to ensure bioimaging data’s value in Life Sciences research and mitigating biases in AI-driven analyses.
Solution
BIO-CODES will evaluate the ISO 24138 International Standard Content Code (ISCC) and apply it to bioimaging data in Life Science research. Generated from digital content using cryptographic and similarity hash algorithms, ISCC ensures data integrity and supports use cases like deduplication, database synchronisation, and data provenance. The project will test routine proprietary formats from imaging core facilities and engage vendors. If ISCC proves useful, recommendations will be made for integrating it into existing workflows and software applications used for authentication and certification of bioimages. The main goal is to assess ISCC's applicability and create a proof-of-concept, with integration into platforms like OMERO to ensure FAIR compliance.
*OMERO is one of the most versatile and widely used platforms for managing bioimaging data, offering tools for storage, organisation, and analysis. By seamlessly integrating globally unique identifiers into OMERO it will streamline AI-driven bioimaging data preparation while ensuring data integrity and FAIR compliance. Standardised authentication processes will enable researchers to share datasets confidently, enhancing transparency and reproducibility. This approach also addresses ethical concerns in AI, mitigating biases from unverified data and promoting reliable AI models in biomedical research.
Scientific Impact
BIO-CODES will enhance transparency and collaboration among researchers by introducing standardised content identifiers in bioimaging workflows. This enhances data reuse, mitigates ethical concerns in AI applications, and improves the reliability of AI models in Life Sciences. The ISCC’s ability to generate unique identifiers directly from digital files ensures ease of use and eliminates the need for manual management like DOIs. Its open-source nature supports decentralised digital content identification and encourages continuous improvement through collaboration among researchers, developers, and institutions.
Results
- High-Performance ISCC Implementation for Bioimaging Data: Developed and released iscc-sum, a Rust-based tool that generates ISCC Data-Code and Instance-Code hashes 50-130x faster than reference implementations, processing data at 950-1050 MB/s. The tool addresses performance bottlenecks in large-scale bioimaging data identification.
- ISO 24138:2024 Standard Compliance and Extension: Implemented two units of the International Standard Content Code (ISCC) with full ISO 24138:2024 compliance via narrow format, plus an extended wide format for enhanced security and similarity matching capabilities in bioimaging applications.
- Cross-Platform Research Software Package: Released open-source software with Python API and command-line interface supporting Linux, macOS, and Windows. The package includes a comprehensive test suite (100% coverage), type annotations, and is distributed via PyPI for easy installation.
- Data-Based Similarity Detection System: Implemented data-defined chunking algorithms that enable identification of similar or duplicate bioimaging files based on actual content rather than filenames. This supports data deduplication and quality control in AI training datasets.
- Multi-Source Data Processing Capabilities: Integrated fsspec support, enabling direct processing of bioimaging data from cloud storage (S3), HTTP/HTTPS sources, and local filesystems through a unified interface, facilitating distributed research workflows.
Publications
- ISCC-SUM: High-Performance ISCC Generation for Bioimaging Data, DOI
Events
- 03-06 June, 2025 | Heidelberg, Germany - ELMI meeting, 25th international meeting of the European Light Microscopy Initiative
- 17-18 June, 2025 | Utrecht, the Netherlands - Innovative Imaging for 3D Cell Biology conference
- 1-3 October 2025 | Freiburg im Breisgau - Galaxy Europe, European Galaxy Days - Presentation of the progress of the BIO-CODES project to the Galaxy community
- 30 September 2025 | NL BioImaging Presentation - Presentation of the progress of the BIO-CODES project to the NL BioImaging community
- 20-21 November 2025 | Berlin, Germany - CytoData 2025 - BIO-CODES Poster presentation to the image-based profiling and bioimage analysis community
- 25-27 March 2026 | Vienna (TU Wien), Austria - FDO Conference 2026 - Presentation of the progress of the biocodes project to the FDO (FAIR Digital Objects) community
- 13-17 April 2026 | Online - Euro-BioImaging: Image Data Community Days - Presentation of the progress of the BIO-CODES project to the Euro-BioImaging community
Communication Material
- Presentation BY Titusz Pan: "BIO-CODES. Enhancing AI-Readiness of Bioimaging Data", Catch-Up Meeting - iscc-sum, 28 March, 2025
- Presentation BY Titusz Pan: "BIO-CODES. Enhancing AI-Readiness of Bioimaging Data", Catch-Up Meeting - iscc-sum, 21 July, 2025
Principal investigator

Dr. Sylvia le Dévédec is an assistant professor and researcher specializing in cell biology, bioimaging, and cancer research. With a PhD in the field of life sciences, she has developed extensive expertise in high-content bioimaging and advanced data analysis, focusing on the integration of cutting-edge technologies in biomedical research. Sylvia's work emphasizes data integrity and reproducibility, which aligns with her leadership of the BIO-CODES project, where she aims to enhance the AI-readiness of bioimaging data. Her research contributes to Open Science initiatives, fostering collaboration across academia and industry. Through BIO-CODES, she is pioneering efforts to standardise bioimaging data, ensuring transparency, FAIR compliance, and the ethical application of AI in life sciences.
