
This article is one in a series addressing the impact of the OSCARS project on Open Science practices in Europe. (Reading suggestion: start with the introduction to the series).
Read the article on Zenodo
In the context of Open Science, repositories are digital platforms for the short and / or long-term storage, management, and/or sharing of research data, publications and other scholarly materials. They serve multiple purposes, such as long-term preservation, computation, archiving, and dissemination.
Platforms such as Zenodo, HAL, GitHub, and repositories from thematic (i.e. domain-specific) research infrastructures have already helped democratise access to preprints, datasets, and code. Looking ahead, a federation of interoperable repositories will further strengthen cross-cluster collaboration within EOSC.
As described in the Strategic Research and Innovation Agenda - SRIA of the European Open Science Cloud - EOSC, EOSC aims to “extend FAIR requirements to all digital objects” and “design and deploy standards and tools” to support the Open Science vision. Repositories are the infrastructural materialisation of these standards – building on metadata schemas, persistent identifiers (e.g., Digital Object Identifiers - DOIs), access controls, and machine-readable interfaces to support automated data discovery, access and reuse. They facilitate the research data lifecycle by offering mechanisms to engage with digital outputs, ranging from the sharing of early-stage materials (such as preprints and datasets) to the promotion of transparency and the acceleration of scientific progress.
By publicly archiving research objects, repositories empower open peer-review and validation. The COVID-19 experience is an example of their value: rapid data and preprint sharing accelerated diagnostics development, epidemiological modeling, and public-health responses. This transparency strengthens trust in science and enhances societal impact.
To transform research by making Open Science “the new normal”, repositories must enable the recognition of diverse digital outputs – data, software, and code – as scholarly contributions. Proper deposition and citation of such outputs in repositories may translate more and more automatically into metrics and credits for research assessments.
Furthermore, it is key that repositories balance two imperatives: they must be “as open as possible”, and “as shared (or closed) as necessary”, i.e. they have to be open while ensuring compliance with ethical and legal regulations, respecting data sovereignty. For example, to respect GDPR (General Data Protection Regulation) for personal data, or to protect intellectual property rights, secure access procedures may be needed. Moreover, to be trustworthy, repositories are encouraged to adopt trusted repository certification, such as CoreTrustSeal, which offers to any interested data repository a core level certification based on the Core Trustworthy Data Repositories Requirements.
For a proper implementation of FAIR repositories, the SRIA calls attention to the foundational need for training data stewards, software engineers, and repository managers. It calls for curricula, certification, and career pathways that professionalise repository-based stewardship.
How have the five Science Clusters addressed the theme and challenges of repositories?
Across all five Science Clusters (in the following, clusters), the challenges related to repositories have been addressed with distinct but complementary strategies: from federated hubs and data lakes (ENVRI, ESCAPE, PaNOSC), to domain-specific workflows and metadata (LS-RI, SSHOC), while training, certification, and community empowerment have been approached in a more harmonised manner.
ENVRI (Environmental Sciences)
To enhance FAIR data practices in a context characterised by the diversity of environmental RIs and the need for interoperability without compromising specificity, the ENVRI Science Cluster developed the ENVRI-Hub, a federated gateway providing access to harmonised data and services across all subdomains of environmental sciences. Both repositories and technologies (e.g. cloud, Virtual Research Environments - VREs) are then integrated into a Community-based Competence Centre (CCC). The cluster also supports cross-cluster collaboration to adopt and refine repository solutions.
ESCAPE (Astronomy, Nuclear and Particle Physics)
The RIs in the ESCAPE Science Cluster have to manage massive volumes of data with high-performance requirements and a need for FAIR alignment. To tackle this challenge, the cluster has developed the Data Infrastructure for Open Science (DIOS) using a federated Data Lake model for exabyte-scale data. The Data Lake acts as a FAIR data repository system with simple access and robust policy enforcement. It supports cross-cluster composability - where composability refers to the ability to combine and integrate smaller and modular components or services into more complex systems, based on Open Science research practices - through integration with VREs and analysis platforms, and provides collaborative tools and software catalogues.
LS-RI (Life Sciences)
The LS-RI Science Cluster faces complex interdisciplinary needs, such as handling sensitive data, and has thus strived to ensure repository alignment with data protection and ethical standards. In addition to developing interoperable data management workflows, the cluster has been maintaining and integrating many trusted repositories, including BioImage Archive, BioStudies, European Nucleotide Archive, European Genome-phenome Archive and PRoteomics IDEntifications Database. These repositories serve as reference anchors for life science data in EOSC and beyond. Complementary services such as WorkflowHub and RO-Crate (Research Object Crate) support reproducibility by linking datasets and computational workflows. The cluster also builds and shares minimum metadata schemas and FAIR Digital Object practices, and, in the framework of the establishment of Competence Centres (CCs), RIs are involved in developing a skills and competencies registry to support repository adoption across communities. Quality assessment tools and terminology definitions for data management in registries are also in the development phase.
PaNOSC (Photon and Neutron Science)
The PaNOSC Science Cluster aims to facilitate FAIR access to high-value, unique experimental data. In this respect, the cluster has been working toward a federated Data Commons across all PaN facilities in Europe, federating search Application Programming Interface - APIs and repositories across sites, connecting metadata and catalogues through standards like Nexus and PaNET, and developing VREs, such as the Virtual Infrastructure Scientific Analysis platform – VISA, and reusable data management tools, such as DS-Wizard.
SSHOC (Social Sciences and Humanities)
The SSH Open Science Cluster (SSHOC) addresses complex (inter)disciplinary needs. It covers a wide range of data types that reflect the cultural and societal dynamics that are the object of study for the many SSH disciplines that come in many formats and modalities, and supports comparable research across the boundaries of languages, regions and periods. SSHOC coordinates a range of infrastructural action lines for the wider SSH RI landscape, among which is the operation and maintenance of the SSH Open Marketplace discovery portal. The portal pools resources from individual SSH repositories and contextualises them for all relevant research communities: tools, services, training materials, datasets, publications and workflows. The knowledge infrastructure underpinning the SSHOC service offer is integrated into the emerging SSHOC Competence Centre (CC).
The contribution of OSCARS to better repository practices
By leveraging the unique capacities and needs of the five clusters, OSCARS enhances the development and consolidation of federated data infrastructures across domains, bringing them closer to being FAIR-compliant repositories – structured to handle diverse data types, access needs, and scales – and facilitating their integration into the broader EOSC ecosystem.
OSCARS actively fosters collaboration across clusters to share repository technologies, reuse repository-related tools and metadata standards, as well as to adopt minimum metadata requirements fundamental to foster Open Science, and align on service maturity and sustainability.
It also supports the composability of repositories and services – enabling modular integration of metadata standards (e.g., DCAT Application profile for data portals in Europe DCAT-AP, Nexus, PaNET), data analysis and workflow management environments (e.g., Galaxy, Jupyter Notebooks, WorkflowHub), discovery tools and APIs (e.g., federated search in PaN, RO-Crate metadata packaging, Rucio data management platform), to ensure repositories can exchange (meta)data and services across domains, as well as support complex, cross-disciplinary workflows, and integrate seamlessly with EOSC Exchange, a catalogue of the EOSC offer and services which are made up of components including onboarding workflow and data transfer services, service and research product catalogues and dashboards, and EOSC resource search, discovery and recommender services - seamlessly.
Also, each cluster has established CCCs to provide technical support for repository development and adoption, disseminate repository-related training, best practices, and tools, and - as in the case of SSHOC - encourage adoption of trusted repository certification. These CCCs serve as knowledge and service hubs for advancing repository capabilities within and across disciplines.
Finally, OSCARS will use a repository network as key anchors for the projects funded via its Open Calls. In fact, all funded projects must deposit their data in trusted open access repositories, which adds to the fact that projects are expected to extend, or reuse repository services and digital objects, and that FAIR compliance is an evaluation criterion in grant applications.
This will create a feedback loop where new projects improve, extend, and validate repository infrastructure.
Below is an overview of the OSCARS funded projects working to make improvements primarily in the area of repositories:



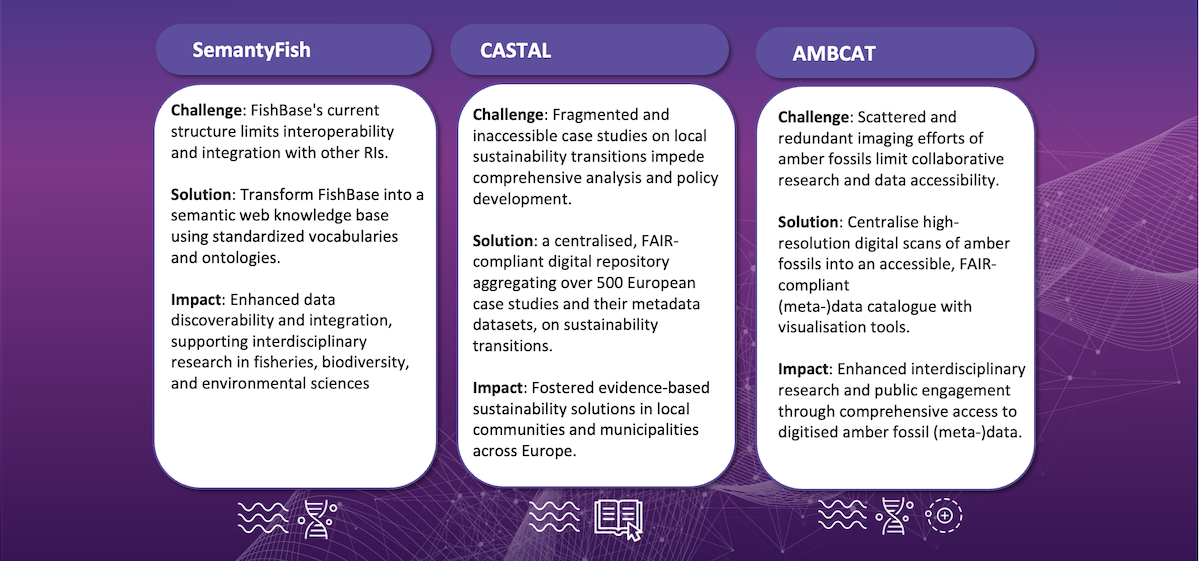
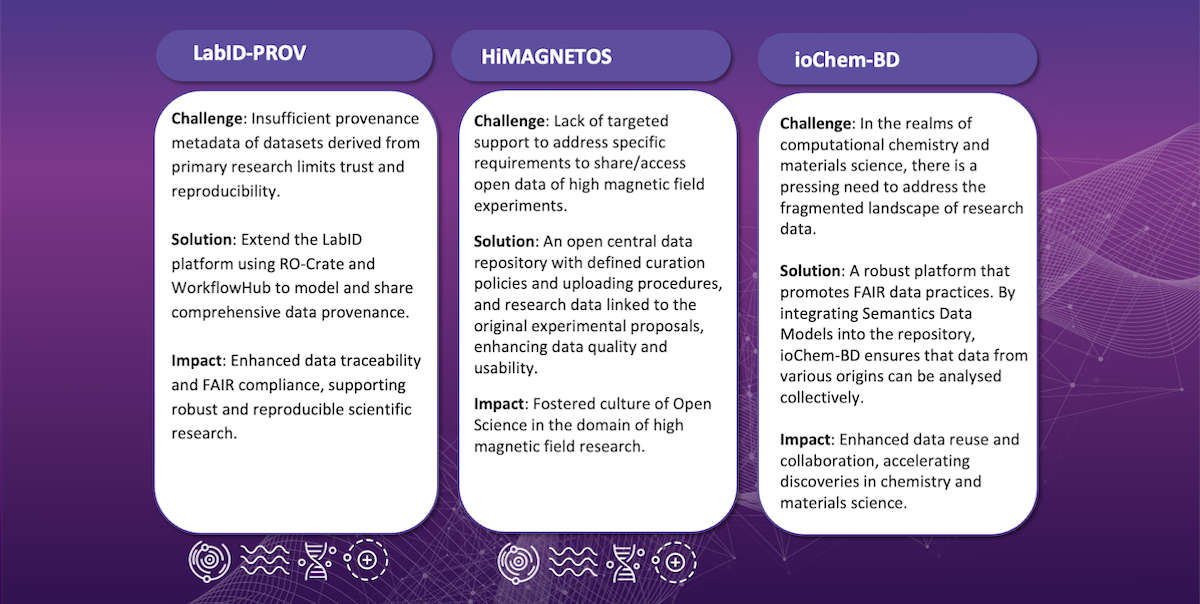
Browse all OSCARS funded projects here
Useful resources
Repositories guidance
- How to choose a data repository
- Repository Guidelines
- OSF | FAIRsharing Collaboration with DataCite and Publishers: Data Repository Selection, Criteria That Matter
Repositories description and recommendations
- Research Data Repository Interoperability WG Final Recommendations
- RDA Common Descriptive Attributes of Research Data Repositories
Repository catalogues and Comparison
- Generalist Repository Comparison Chart & https://fairsharing.org/GeneralRepositoryComparison
- Thematic Research repository catalogue: https://www.re3data.org/
- Thematic Research repository catalogue: DataCite repositories Catalogue
- Registration of EOSC Research Product Catalogues in the EOSC EU Node
Repository certification
- Core Level: CoreTrustSeal
- Extended Level: DIN 31644/nestor Seal
- Formal Level: ISO 16363
- Certified repositories: https://amt.coretrustseal.org/certificates/
Authors
Nicoletta Carboni (CERIC-ERIC), Romain David (ERINHA), Franciska de Jong (Utrecht University), Jonathan Ewbank (ERINHA), Darja Fišer (CLARIN ERIC), Fabio Liberante (ELIXIR), Justine Thomas (CNRS-LAPP), Friederike Schmidt-Tremmel (Trust-IT).
DOI
http://doi.org/10.5281/zenodo.17224742